TechTalk: Addresses are Simple? Ha!
GeoPhy’s magic for ensuring you find properties

At GeoPhy, we provide our users scores of different characteristics about the US real estate market, including:
- Physical description of a property (its size, age, and even roofing materials)
- Property transactions and their historical value, as well as ownership
- Amenities (ranging from pools and tennis courts to microwaves)
- Rent data and its change over time
- Maintenance expense and tax data
- Unit mix, or the number and type of apartments present
However, we don’t just present this data from one data set. GeoPhy works with multiple property data sources. We develop cross-source connections to create comprehensive and elaborate property records.
To link these disparate records we use Assessor Parcel numbers, owner names, and the geographic location of properties – most prominently, their address.
That address can be a physical building or an apartment in that building. It can also be a parcel that contains multiple buildings or clusters of property parcels. To build our robust database, we need to ensure addresses are referring to the same properties in different datasets so we are comparing apples to apples.
Without an address, we cannot provide a record’s information to our users. With an address, we can guarantee the uniqueness of this information to a property.
How difficult can an address be?
From data analysis or wrangling, we data scientists know what an ideal address looks like. It has a street number, street name (including suffix), possibly a pre direction and post direction indicators, as well as information about the city, county, and state where a certain property is located – almost always including a postal code.

Most of GeoPhy’s data follows this structure. For a sizable share of property data, however, that is not the case. Formatting differences and noise in data are present in addresses. To link cross-source property records and get comprehensive records, we might use latitudes, longitudes, or assessor’s parcel numbers as alternatives. But ultimately, the best approach is to fix specific property records so they more closely follow the ideal address structure. Among the problems we encounter are:
- Formatting differences: Various data providers prefer different address formats. For example, one vendor’s 123 Main Street could be another vendor’s 123 Main St. The same goes for any other word that can be abbreviated: North, West, East and South vs. N, W, E and S; Avenue vs. Ave; Circle vs. Cir. They mean exactly the same, but can trip up exact address matching.
- Human error: Human-curated records can contain minor errors such as spelling mistakes or inconsistent letter capitalization, unnecessary punctuation, or similar issues. Did you know that the state of Texas can be spelled at least 8 different ways?
- Different approaches in naming cities: Differing data sources can cite the same address in New York City or Brooklyn. As an address and postal code together establish an address’s uniqueness, we prefer to use FIPS codes or state names in our models rather than city names.
- Information can change and be updated: Address information is not static. Sometimes the change is easily caught. A shift in address information is noticeable, but any changes in the assigned postal code values for a certain area are not. The speed with which our vendors change addresses can impair our ability to match these records when different data sources have different postal codes due to different update schedules.
- Geographical granularity of property records: Some records contain information about apartments, units, suites, or office numbers. While this data can be helpful for certain analyses, it can skew exact address matching.
- Range of street numbers: Bigger property developments sometimes have an address as you can see in the picture below:
We have no clear indication whether this street number range refers to every single street number between 710 and 760, or only even numbers that are contained in this range and that would be located on the same side of the street. For issues like this, we need a source of truth and other tools to validate our assumptions.

- Street corners: Some manually curated datasets display property records as in this example:
Appraisers might know which specific building this record refers to based on the size in units, age of the property, or their knowledge about the area. Without this information, we end up with the difficult decision of deciding which of the four corners is the actual building for this record.

- Additional address field information: Records sometimes provide additional information for addresses. The extra information can include the property’s previous address, its name (e.g., Empire State Building), and other details. This information might be useful as it gives additional insight and points of reference, yet if left as is it just skews our data when we wrangle more than 160 million rows of property records.
- Multiple mailing addresses: Bigger properties (think: garden properties) sometimes provide multiple addresses in a single cell. In the following example you can also see a street number range:
For this type of address, we need to separate these addresses in order to match the records to another source’s 800 West Walnut Avenue as a single record.

Testing the Tools
We can use different address standardization and geocoding tools to deal with most address string irregularities. These tools take an address, check if it exists, and return it with a standard format. They should be able to handle problems 1-4 above with ease, making our datasets cleaner and more homogenous.
To test how geocoding and address standardization tools handle the more complex address issues with problems 5-8, we conducted an analysis.
We compared the performance of Smartystreets, Geocodio, and the Google Geocoding API. Our test used the same address samples, even without cleaning the input. We especially wanted to see how they performed with irregular addresses known for difficulties in cleaning and wrangling. We also wanted to understand whether these standardization tools complement each other and whether specific tools better handle certain complex address groups.
The sample address groups included:
- For a baseline assessment, addresses that follow the ideal address structure
- Street corners with no street numbers in the address string
- Address fields with multiple addresses in one cell
- Addresses with street number ranges
- Addresses with apartment and/or unit information
- Addresses with additional, not address related information.
We gathered these samples from four different data sources by querying the data for either specific markers (e.g., semicolon for multiple addresses) or keywords (e.g., apt or unit). We extracted a CSV file with 2 columns: unique identifier (property ID) and full address information joined in one cell (address, city, county, postal code and state). We fed these files into Smartystreets, Geocodio, and the Google Geocoding API for validation.
We set each tools’ validation criteria to be strict. If the tool was not certain, it would not mark this address validated.
Results from geocoding and address standardization tools
We measured the results by the data source and address complexity group. There is a clear trend. Each of the tools standardized and validated the address if it was close to the ideal address structure. The validation rate drops for addresses with more complex components, such as street ranges, street corners, and others:
- Address standardization tools were least likely to validate multiple address groups; all three failed to provide output addresses for more than 40% of those address samples
- Groups of addresses with apartment information, that contain street ranges, and that have additional information are most likely to be validated by all tools or by the Smartystreets/Geocodio pair of tools.
- Google Geocoding API handles street corner addresses the best, with 34% of that sample validated; Smartystreets and Geocodio’s performance was considerably lower.
- Google and Geocodio are more likely to guess a valid address. Smartystreets outputs its validations against the US Postal Service’s robust Coding Accuracy Support System (CASS) certification. Its output is one the USPS recognizes as a mailable address. Google Geocoding and Geocodio APIs do not embed this requirement in their address standardization techniques.
The results of our tests can be seen in the images below:
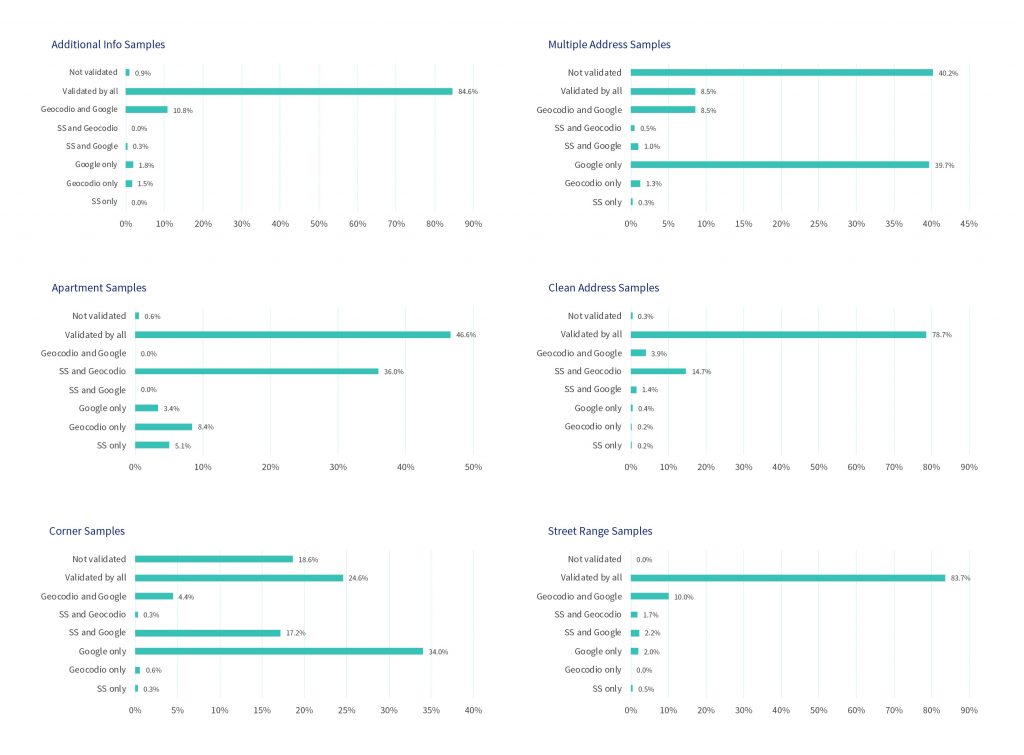
Quality of address standardization
We tested tools intended to standardize addresses, not necessarily parse them. The good news is that – if an address string approximates the ideal address format explained above – these tools do an excellent job of validating the addresses (95% validation rate with at least 2 tools) and provide exactly the same standardization results:

But for complex addresses, these standardization tools might mark the output as validated even when their results are not the same as an appraiser would do it. Parsing, as we noted, is not a part of what they were designed to do. In the best case scenario, the standardization tool recognizes that the address string pattern is more complex than expected and provides no validation result:

Worse than giving us the false impression that the addresses are valid, in some cases the data might be damaged. For instance, we would need to recognize that the address did not have a unit number and now it has it.
For precise results like those GeoPhy needs, address standardization tools can only deal with clean, structured, and parsed data. They cannot solve inconsistencies and formatting specifics present in data. Skipping address parsing can skew our data and cause us to lose information.
In part II of this series, we’ll cover how GeoPhy parses address records before verifying them.
————————–
The series has two parts:
Part 1: We test various methods for confirming difficult addresses.
Part 2: We detail GeoPhy’s approach to parsing addresses before verifying them.


