TechTalk: Addresses are Simple? Ha! Part II
Parsing data before validation

In part I, we tested how SmartyStreets, Geocodio, and the Google Geocoding API handle validation and standardization. A standard address matters to us at GeoPhy because we use common addresses to tie together datasets from different vendors.
Our main takeaway: these data tools handle addresses that approximate an ideal address really well (123 Main Street, Anytown, State, ZIP), but they trip up on more complex addresses such as those with street address ranges or multiple addresses. That’s not an unexpected result as none of these tools is designed to parse an address before attempting to validate it. Here’s how we handle that parsing at GeoPhy before validating an address with those tools.
Solution: Address Parsing
Parsing an address cleans its fields by separating records that need to be split. Parsing creates clean, API-readable address strings.
Initially, we looked for patterns in address strings. We searched for specific symbols and keywords, associating them with certain characteristics and logic on how it should be processed. When trying to implement this strategy, however, we ran into several roadblocks.
We work with numerous data sources. Use of keywords, symbols, and general formatting differs from source to source. One vendor uses the word and to separate two different street numbers. A different source can provide the same address as a street corner with no street number. One of our vendors uses the semicolon symbol in 6 different address structures, and the ampersand symbol in at least 8 different ways. Multiplying the number of special characters and keywords by the number of sources, the possible combinations quickly become unreasonable. No single address parsing script could handle them all.
Furthermore, this approach to address parsing is not sustainable as a long-term strategy. Our vendors update the data regularly. The list of address component combinations would not be static, meaning the script would require maintenance and nitpicking small issues and exceptions to be effective.
A Different Approach to Parsing
For the complex address groups, there is a commonly shared structure. Generally speaking, the address string consists of numbers first + then a street name + maybe more numbers + another street name + more repetitions of the same sequence.
All special symbols considered in the address parsing sequence are, in fact, separators. Commas, semicolons, and ampersands separate address components. They do not provide additional value, however. (Hyphens, on the other hand, by themselves provide additional content value. They indicate that the street numbers in an address string are not the only street numbers in that address.)
GeoPhy’s approach to parsing complex addresses, then, became to treat all the address strings in as much the same way as possible. We look for common characteristics and account for some exceptions, rather than trying to look for all combinations possible.
For example, we use the address 120, 122, 130-133 Florence Drive & 547, 549, 581, 601, 606-610, 612 Woodmere Drive below:
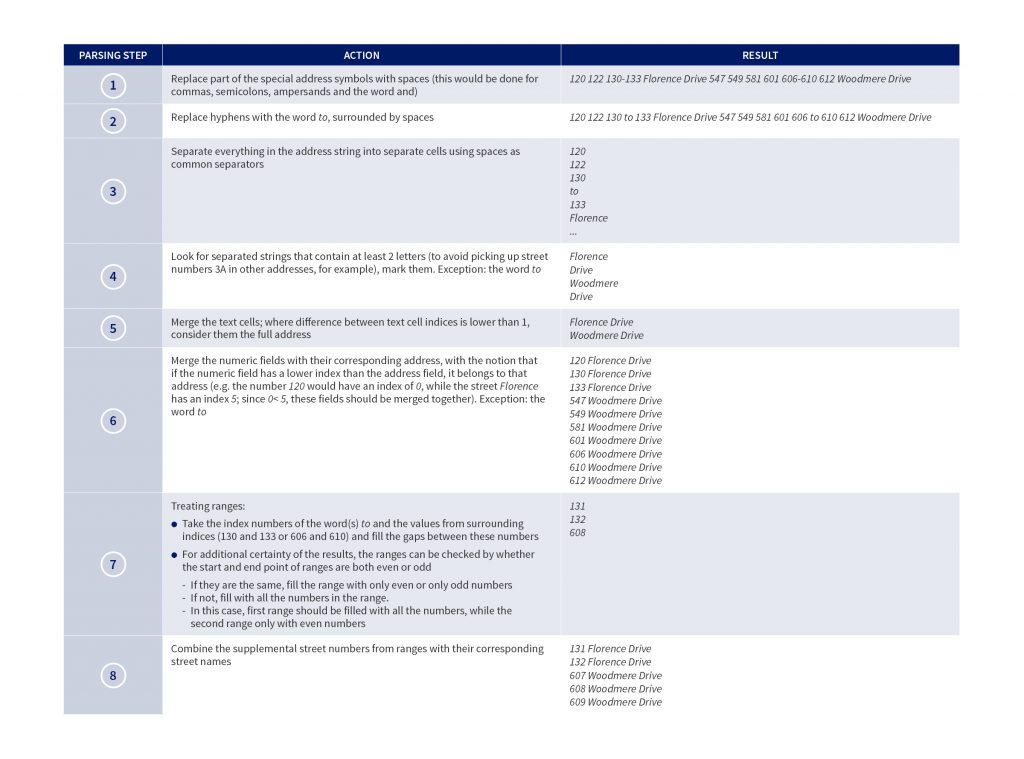
After these steps, the addresses can be stored for further validation and processing.
Small note: if an address string contains an apartment number or any other lower-than-building granularity levels, the sources do not group it together with other addresses. It requires a different parsing methodology altogether.
Validating Street Ranges
As noted earlier, street ranges do not have a common framework. If the starting and end points of the range are both even numbers, we might be correct to fill the entire range with the respective even values. Or we might be correct if the starting number is even and the end number is odd to fill the range with all the numbers in between them.
It is also not uncommon, however, to see street numbers have a bigger step between each house number. Steps of 5 (i.e., 10 to 15 to 20), 10, 50, 100, or even 1000 are used. If we don’t account for this, our parsing can introduce a lot of useless addresses to our dataset. This is why we need to validate if these Frankenstein addresses we’ve added are true using one of two methods.
First, we validate the addresses against a list of all addresses registered by USPS. If the address is not present in this table, we deem it invalid and toss it.
Another approach is to use one of the address standardization tools tested in part I. If the tool deems the address to be invalid, we can toss it and continue our work with the valid data.
Conclusions
Data analysts and engineers share a quote on LinkedIn: ”Data wrangling is 10% skill and 90% anger management.” The more data we have, the more likely we are going to have irregularities that make our journey from point A (data) to point B (users) more challenging. Accepting that noise instead of ignoring it makes it easier to deal with.
Ultimately, we found that even the most complex addresses have a pattern that we can work with. By seeking out these patterns, we increase our data’s size and are able to use it more successfully in our models and applications. By cleaning and improving our data, we continue to provide valuable real estate insights to our users.
————————–
The series has two parts:
Part 1: We test various methods for confirming difficult addresses.
Part 2: We detail GeoPhy’s approach to parsing addresses before verifying them.


